들어가며
현재 진행하는 프로젝트에서는 세개의 서버를 멀티모듈을 통해 관리하고 배포중에 있다. 하지만 이 배포전략에 대해서 많은 한계점이 존재한다. 이번 게시글에서는 한계점에 대해 분석해 보고 해결방법의 종류들에 대해 알아보는 시간을 가져볼 것이다.
현재의 배포 플로우

Server1에서 새로운 기능 개발을 위해 작업 a를 진행하고 Server2에서 새로운 기능개발을 위해 작업 b를 진행한다고 가정하자.
1. 스프린트 기간동안 Server1에서 작업 a를 진행하고 Server2에서 작업 b를 진행한다.
2. 스프린트 기간동안 작업 a와 작업 b가 모두 병합되어 개발이 완료된 develop 브랜치가 된다.
3. 개발이 완료된 develop브랜치의 코드를 릴리즈한다.(2번과 3번 사이에 QA가 존재하지만 위 그림에서는 생략한다.)
문제점
사실 작업 a와 작업 b가 동시에 끝나면 문제가 없다. 하지만 아래와 같은 경우에 문제가 발생하게 된다.
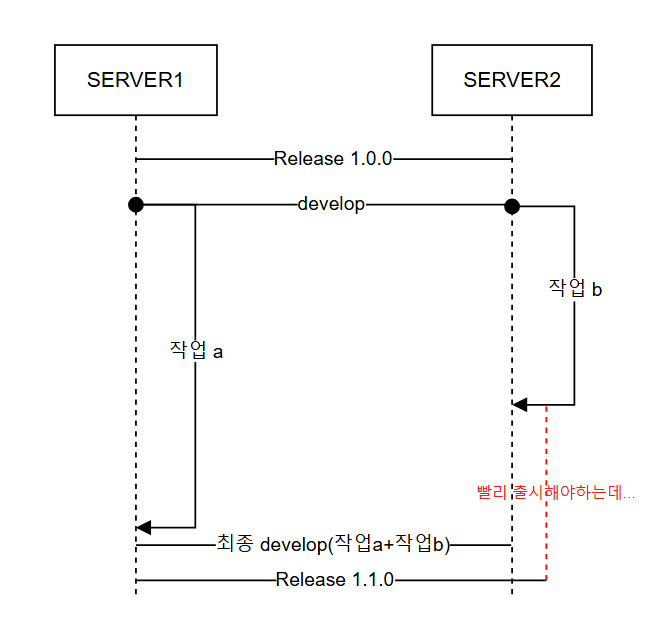
예를 들어 작업 b가 긴급한 작업이라 급하게 처리 후 빠르게 배포를 해야한다고 가정하자. 작업 b가 먼저 완료되었어도 작업 a 때문에 배포를 할 수가 없게 되는 상황이 발생한다.

그렇다고 해서 작업 b가 완료된 시점에서 바로 릴리즈를 진행하면 develop에서 완성된 작업 b와 개발중인(미완성 상태의) 작업 a가 release 브랜치에 들어가게 될 것이고 검증되지 않은 코드가 운영 서버에 올라간다는 것은 매우 치명적인 결과를 초래하게 된다.
위의 예시로 보았을 때 문제점이 발생하는 이유는 크게 세가지로 정리해 볼 수 있다.
1. 배포할 서버의 종류가 여러개이다.
2. server1과 server2의 develop 브랜치가 공유되어 있다.
3. server1와 server2의 배포 주기를 무조건 같게 가져가야 한다.
해결 방안은 없을까?
1. 브랜치 전략 개선

server1과 server2의 브랜치를 따로 관리하는 방법이 있다. server1과 server2의 develop 브랜치를 따로 생성한 후 server1과 server2의 새로운 기능이 완성되면 server1과 server2에 대해 따로 release 브랜치를 생성 후 main에 병합하는 방법이다.
해당 방법을 사용하면 server1과 server2는 별도의 브랜치로 관리되므로 각 서버에 대한 기능이 완성되면 main브랜치에 병합하면 문제점이 해결된다.
하지만 이 해결 방안에는 감수해야 하는 잠재적인 위험이 도사리고 있다. 바로 공통 의존 모듈에 대한 관리이다.

위의 사진은 server1과 server2가 의존하고 있는 모듈에 대한 구조이다. server1을 구동하기 위해서는 server1-api, infra, domain, common모듈이 필요하고, server2를 구동하기 위해서는 server2-api, infra, domain, common 모듈이 필요할 때 infra, domain, common 모듈은 두개의 서버에 공통으로 의존되는 모듈이다.
이중 제일 큰 문제점은 domain모듈에서 발생하게 된다. domain 모듈은 DB의 스키마를 나타내는 Entity들의 코드와 DB에 접근하는 데이터 액세스 레이어인 Repository들이 구현되어 있는 모듈이다. 즉, DB와 관련된 코드들이 들어있다.
그렇기 때문에 별도의 브랜치로 서버를 관리한다고 해도 domain 모듈에서 변경사항이 발생하게 되면 모두 업데이트를 해주어야 하는 단점이 존재한다. (사실 infra 모듈과 common 모듈도 동일하긴 하지 크게 치명적이지 않다.)

다행히도(?) 위의 그림과 같이 cherry-pick을 통해 작업을 진행하면 해결되는 문제이기는 하나 개발자가 cherry-pick을 진행하는 일은 여간 귀찮은 일이 아니기도 하고 실수가 발생할 확률이 높다는 단점이 존재한다.
2. MSA의 도입
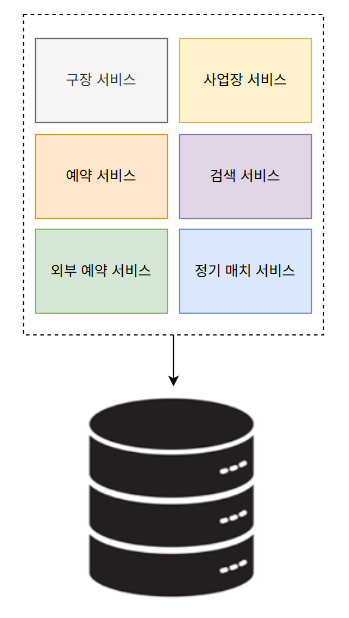
현재 프로젝트는 하나의 메인 DB에 모든 데이터와 로직을 집중시키는 모놀리식 아키텍쳐를 사용하고 있다. 모놀로식 아키텍처를 사용하고 있기 때문에 해당 아키텍처는 서비스의 규모가 커질수록 여러 서비스가 동시다발적으로 메인 데이터베이스를 사용하게 되고 이로 인해 아래와 같은 부작용들이 발생하게 된다.
1. DB 부하 증가로 인한 성능 저하
- 검색 서비스, 예약 서비스, 정기 매치 서비스 등 여러 서비스가 동일한 DB에서 데이터를 조회/수정하는 경우, DB 부하가 증가
2. 장애 발생 시 전체 서비스에 영향 발생
- 예약 서비스에서 잘못된 쿼리를 실행하여 DB에 락이 걸리거나 CPU 사용률이 급증하는 경우, 같은 DB를 공유하는 다른 서비스 들도 영향을 받아 전체 서비스에 영향을 끼칠 수 있음.
3. DB의 스키마 변경 시 서버의 코드 수정 부담 증가
- 위에서 설명한 domain 모듈 같이 변경이 발생하면 모든 서버에 대해 변경사항을 적용해야 한다.

하지만 MSA 아키텍처를 사용하여 서비스 별로 DB를 분리하고 독립적으로 배포하게 된다면 문제들을 해결할 수 있다. 또한 아래의 장점을 가지게 된다.
1. 장애 격리 및 서비스 독립성 증가
- 특정 서비스의 DB에 문제가 발생해도 다른 서비스는 정상적으로 운영 가능하다.
2. 트랜잭션 충돌 감소 및 성능 최적화
- 각 서비스가 자신만의 DB를 가지므로, 동시 트랜잭션 충돌 문제를 줄일 수 있다.
- 각 서비스에 맞는 다양한 DB를 사용할 수 있다.1
3. 확장성(Scalability) 증가
- 서비스 별로 독립적으로 DB를 확장할 수 있어, 특정 서비스의 부하 증가에 대응이 가능하다.
4. 보안 강화 및 데이터 접근 제한 가능
- MSA에서는 각 서비스가 자신의 DB만 접근 가능하므로, 특정 서비스에서 불필요한 데이터를 조회하지 못하게 할 수 있다.
그럼 MSA를 적용하면 아까의 멀티모듈의 구조가 어떤 식으로 변경될까?

server1에서 사용할 domain, infra 코드, server2에서 사용할 domain, infra 코드를 분리하여 독립적으로 배포될 수 있도록 분리된 구조를 띄게 된다. 힘들게 cherry-pick을 진행할 필요가 없어지는 것이다!! (설계에 따라 다양한 방법이 나올 수 있다.)
하지만 MSA 아키텍처에도 단점이 있다.
1. 각자 배포한 서비스에 대해 다른 서비스와 연계가 잘 되는지 확인해야 한다.
2. 서비스 간 호출 시 REST API 사용으로 인한 통신비용, Latency(지연시간)가 증가한다.
3. 서비스가 분산되어 있어 트랜잭션 관리가 쉽지 않다.
한줄로 요약하자면 어렵다는 뜻이다....
하지만 개인적으로 위의 세가지는 MSA 도입으로 인해 발생하는 단점으로 바라보는것 보다는 다양한 방법을 통해 해결할 수 있는 문제들이라고 생각한다.
마치며...
지금까지 현재 서버 배포방식의 문제가 무엇인지, 해결 방법이 어떤 것이 있는지 살펴보았다. 이중 MSA에 대해 알아볼 것이고, MSA에 필요한 지식인 EDA, API Gateway, Kafka 등을 천천히 학습해 나갈 것이다.
- 예시 : 검색 서비스는 읽기 성능을 최적화한 NoSQL을 사용, 예약 서비스는 트랜잭션을 보장하는 RDBMS를 사용 [본문으로]